insights
Expert perspectives on AI integration, platform engineering, and building tools that make complex systems more accessible.


most popular
The insights that resonated most with our readers
archive
Posts from 2022-2024, covering Salesforce DevOps, CumulusCI, and the original Muselab vision. Some concepts have evolved since then—our approach has broadened beyond Salesforce.
2024
7 posts
Securing Salesforce DevOps: Multi-Job Workflows in GitHub Actions
Getting it working is not the same thing as getting it working securely! Here's how to split GitHub Actions workflows without compromising your org credentials.

Introducing The Composable Delivery Model
19 Sep 2024...
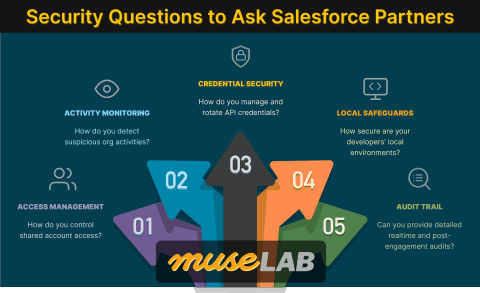
5 Critical Security Questions to Ask Your SI Partner
Dreamforce is just around the corner. Before you hand over the keys to your org, here are five questions you need to ask—questions that became painfully relevant after the 2025 Gainsight breach.
Securing Salesforce DevOps: Least Privilege Access Control
CI/CD credentials are the scariest credentials in your Salesforce ecosystem. Here's why, and what to do about it.
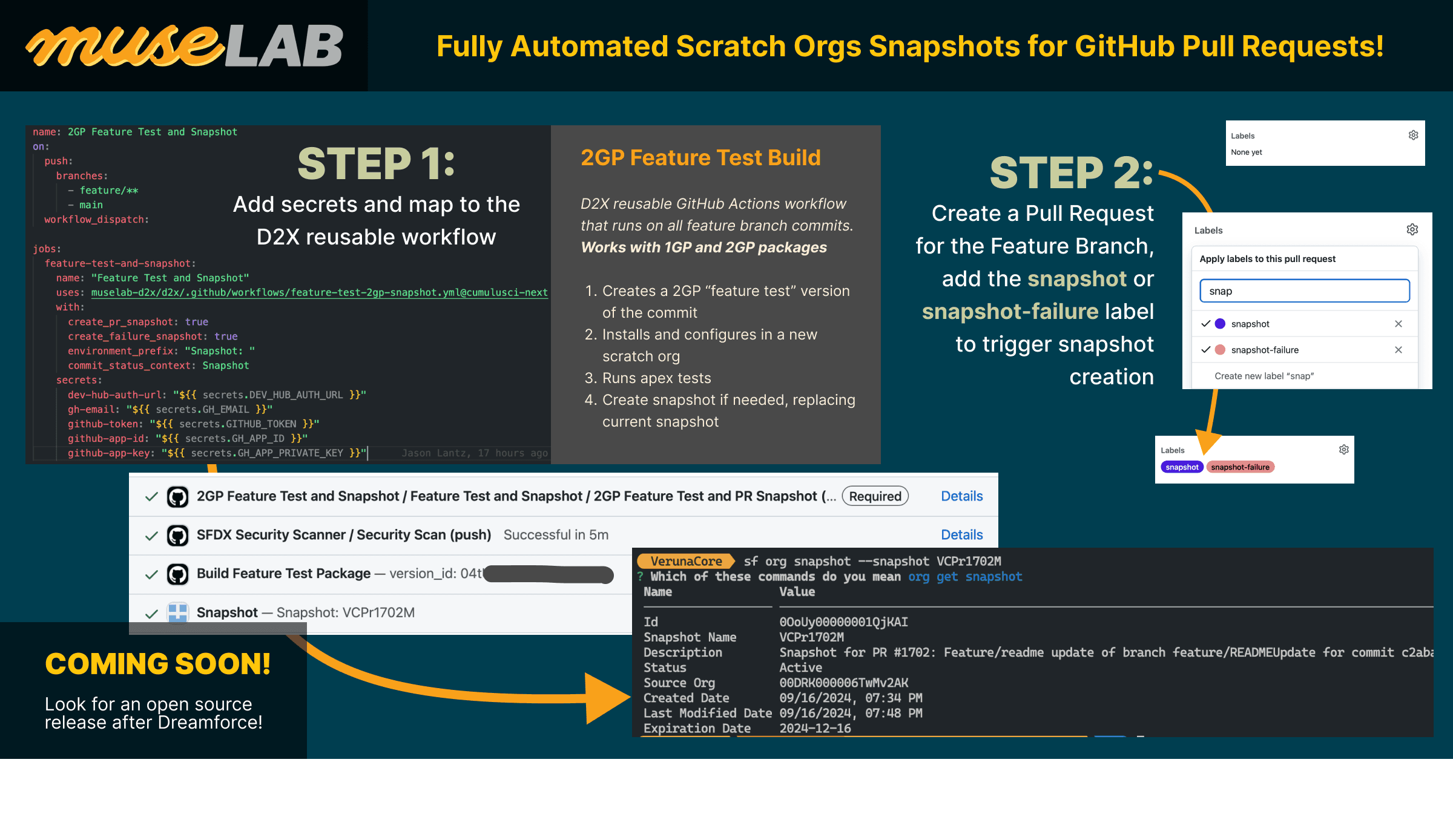
Develop, Test, and Fix Faster with Scratch Org Snapshots
3 Sep 2024...
Webinar Recap: Salesforce ISV DevOps
5 Feb 2024...

Consistent, Reliable Retrieval to Source Control
12 Jan 2024...
2023
7 postsCumulusCI for sfdx (or sf) Developers
2 Dec 2023...

Well-Architected DevOps with D2X
5 Oct 2023...
Building Career Pathways to Expertise
27 Jun 2023...
Three Principles for Building Resilient Products
30 May 2023...
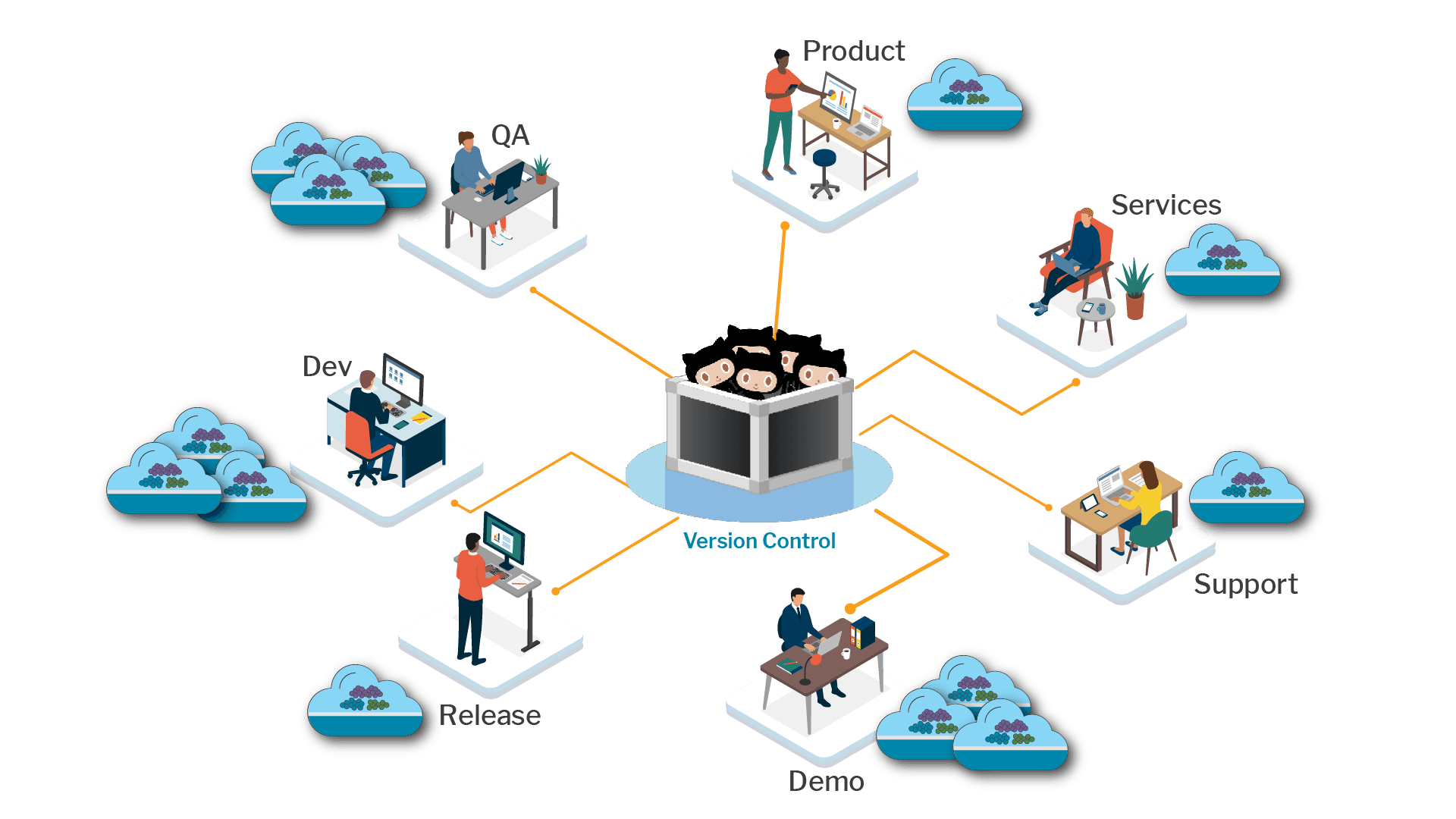
Starting from Scratch
11 May 2023...
Case Study: D2X Transformation at VIIZR
How a startup ISV achieved 480% first-year ROI by adopting the Product Delivery Model and CumulusCI—our first D2X trailblazer success story.
Don't Hire a DevOps Engineer, Create a Culture of DevOps
20 Feb 2023...
2022
10 posts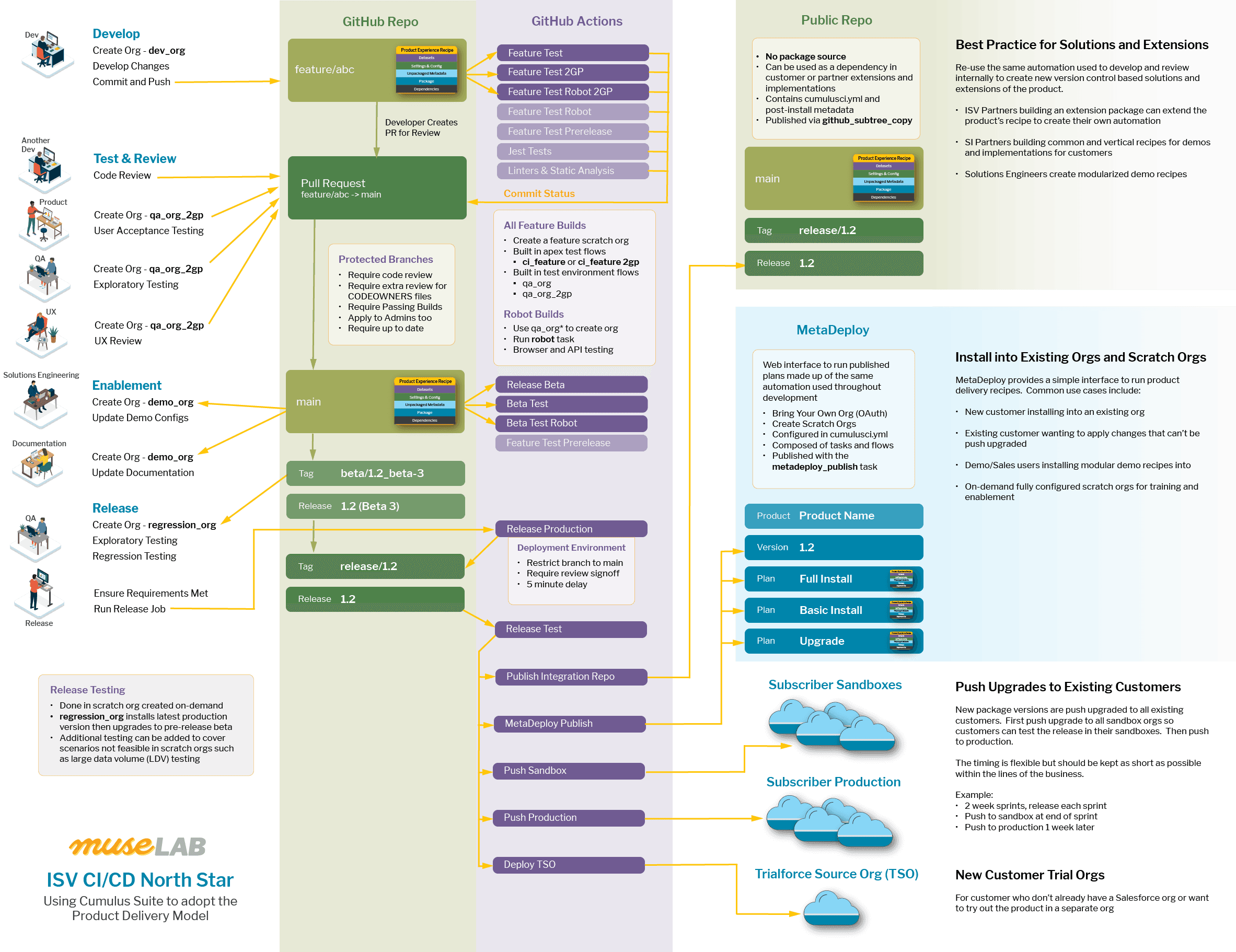
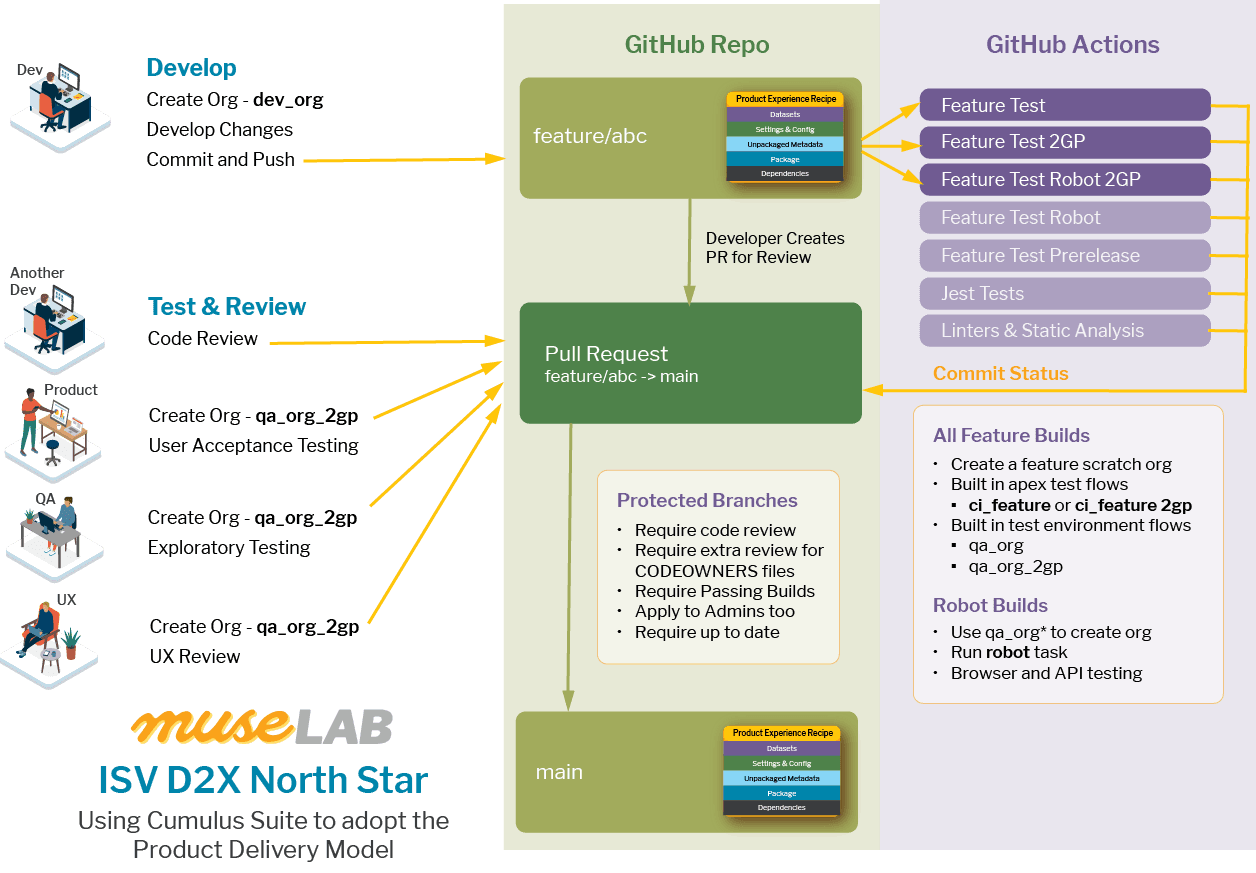
ISV Development to Delivery Experience (D2X) North Star
31 Oct 2022...

Advantages of CumulusCI's Second-Generation Packaging (2GP) Implementation
27 Oct 2022...

CumulusCI is a Misnomer, That's My Fault
CumulusCI is often confused with continuous integration applications for good reason—it has 'CI' in the name. Here's the history of how the name came about and what CumulusCI actually is.
Namespaced Scratch Orgs and the Product Delivery Model
21 Oct 2022...

CumulusCI's Metadata Transformations
19 Oct 2022...
3 Approaches to Pre-Release Testing for Salesforce ISVs
It's quite common for Salesforce ISVs to wait until they've cut a production version of a package to fully regression test it. This is due to one primary constraint of Salesforce's packaging
Foster a Culture of Debate in Engineering Teams
14 Oct 2022...

The Release Subway
5 Oct 2022...
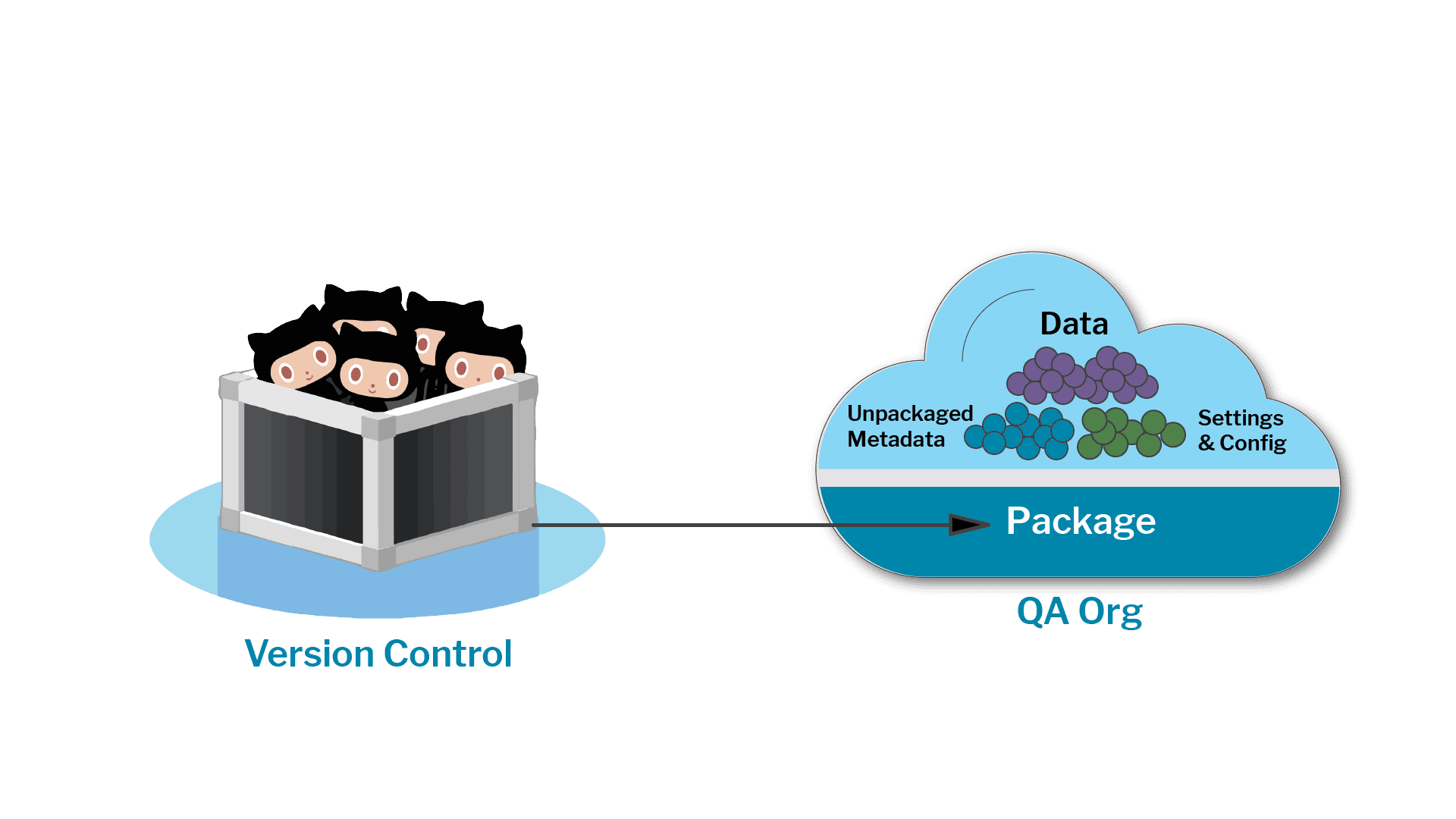
A Product is More Than a Package
What does it take to create fully usable experiences of your AppExchange product? Odds are it's a lot more than just installing a package version.
CumulusCI's Task Framework
3 Oct 2022...